The XperienCentral search engine is based on the popular open source search engine Lucene. The Lucene core code is used for the search service, querying and indexing. A lot of additional functionality has been added to deal with XperienCentral-specific content, structure, security and architecture. For more information on Apache Lucene see http://lucene.apache.org/.
In This Topic
Overview
The following shows a schematic overview of the XperienCentral search engine:
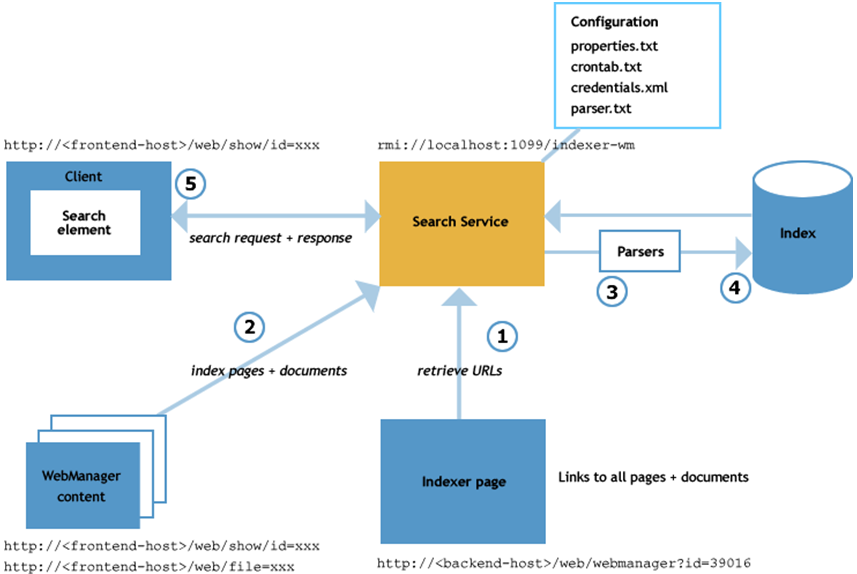
Filling the index with documents is done in three steps: crawling (1)-(2), parsing (3) and indexing (4). Retrieving search results from the index is done from a client such as a page in XperienCentral with a search element (5), from the Setup Tool, or from a command line client.
Crawling
Retrieving the documents starts with retrieving the URLs of all documents and pages. XperienCentral provides links to all items that should be indexed on the indexer page. This page contains references to:
- Pages of all channels
- Content Repository items created in the last 5 days
- Documents (uploaded to a Download element)
- Special content types
The URL of the indexer page is configured in the properties.txt file (metaurl parameter) and is the default start page in the Setup Tool. The search engine crawler retrieves all the URLs from the indexer page and creates requests for each of the documents. Requests are always sent to the frontend in order to benefit from existing caching and to take authorization and personalization into account. With the default configuration, the crawler only indexes links from the indexer page but does not follow links in the retrieved documents. This means the default index depth is 1. An index depth of 1 ensures that the indexing process is efficient and that no outbound links (links outside the channel) are found and indexed.
A request for a document is not only a direct request for the document - additional meta information is requested as well. This extra meta information is provided by the indexer page by requesting the indexer page with an additional document= parameter. For example, to index the homepage on local XperienCentral installation, the crawler requests the URL http://localhost:8080/web/webmanager?id=39016&document= http%3A%2F%2F127.0.0.1%3A8080%2Fweb%2Fshow%2Fid%3D26111. The underlined value is the URL-encoded URL of the homepage. When this URL is requested an XML result is returned which looks similar to the following:
<document> <langid>42</langid> <contenttype>page</contenttype> <date>2007-12-24</date> <webid>26098</webid> <pagepath>p26111</pagepath> <pagepath_00_name>Home</pagepath_00_name> <pagepath_00_url>http://127.0.0.1:8080/web/Home.htm</pagepath_00_url> </document>
Parsing
All retrieved documents are parsed before they are stored in the index. All documents are converted to a plain text format. Office (Word, Excel) and PDF documents are converted with external programs. These programs are usually executable files and they are configured in <searchengine-directory>/conf/properties.txt. The mapping between document type and converter is configured in <searchengine-directory>/conf/parser.txt. The mapping can be based on both file extension and content-type, which is retrieved from the HTTP header. For more information about the parser.txt file see Parser Configuration.
Indexing
The index stores the indexed information. In fact, it is a small database that is tuned for fast information retrieval. It is also similar to a database because it contains a set of documents (one indexed document is one document in the database) and every document has a set of fields. Notice the similarity between tables and table fields. Before documents are stored in the index they go through three processes. The first is the normalizing process. In this process characters are converted to normal and lowercase equivalents. For example "ç" is converted to "c", and "C" is converted to "c". By doing this a user will get search results when searching for "barcelona" instead of "Barçelona".
The second process, tokenizing, breaks up words and sentences in different so-called tokens. These tokens are counted and the amount of tokens inside and outside the document is stored. The number of tokens is one of the important factors for relevance. For example, when a document contains 9 times the token "car", and the rest of the website contains only one other "car" token, then this document is highly relevant when searching for "car" or "cars".
The third process is storing all the information in the index. Storing information is done by creating an entry for every document and filling all the fields of a document. Every field has a relevance factor that indicates how important the field is for the document relevance. Some of these factors can be set by changing the corresponding parameters in the properties.txt file. The default settings are:
factor.title=10
factor.description=5
factor.keyword=10
factor.location=1
The title and the keyword are the most important fields.
Whenever you change any of these settings be sure to fully reindex the site.
Searching
Once a website has been successfully indexed, you can perform tests on the search index. The XperienCentral search engine is a customized version of the popular open source search engine Lucene. The syntax for queries is almost the same as Lucene. The entire syntax is described here: https://lucene.apache.org/core/2_9_4/queryparsersyntax.html. For a detailed overview of the scoring algorithm of the Lucene search engine see https://lucene.apache.org/core/3_6_0/scoring.html
Index structure
The XperienCentral search engine has a variable set of fields depending on the type of documents that havebeen indexed. Below is a list of the most import fields that are always part of the search index:
| Field Name | Description | Example Values |
|---|---|---|
| Contains URLs to the child pages of this document | http://127.0.0.1/web/show/id=26111/langid=43/dbid=2/typeofpage=75501 |
| The content type. | Possible values include: |
| The description of the document taken from the HTML | This combination enables continuous web innovation |
| The hostname of the document. | 127.0.0.1 |
| A keyword. | WebManager |
| Meta keywords taken from the HTML | WebManager |
| The language ID of the document. | 43 (=Dutch), 42=(English) |
| The URL of the document. | http://127.0.0.1:8080/web/News/import-wcm.swf.htm |
| The date the document was created (only relevant for Word documents or PDFs, less for HTML pages). | 20080922102830396 |
| The date the document was last modified. | 20080922102830396 |
| The date the document was first indexed. | 20080922102830396 |
| The combination of web ID’s that lead to the document. | p26111p70532 (the document is below the homepage (id=26111) and a subpage (id=70532) below the homepage) |
| The name of the root page of the document. | Home |
| The URL of the root page of the document. | http://127.0.0.1:8080/web/Home.htm |
| The name of the level xx page that leads to the document. The range of xx is between 00 and the depth of the website. | |
| The URL of the level xx page that leads to the document. | |
| The ID of the channel to which the document belongs. | 26111 |
Other fields that can be part of the index are:
- Special fields from indexed PDF, MS Word and MS Excel documents. Possible fields include
author,creator,encrypted,filesizeand so forth. - All
<meta>tag fields found in HTML pages. For example, when a page is indexed that contains the code<meta name=”mySpecialField” content=”mySpecialContent”/>, a new field will be created in the index with the titlemySpecialField. For this page it will contain the valuemySpecialContent- for all other documents it will be empty.
To view the contents of a search engine index see Analyze the Search Index.